前言
大家好,我是阿光。
本专栏整理了《PyTorch深度学习项目实战100例》,内包含了各种不同的深度学习项目,包含项目原理以及源码,每一个项目实例都附带有完整的代码+数据集。
正在更新中~ ✨
🚨 我的项目环境:
- 平台:Windows10
- 语言环境:python3.7
- 编译器:PyCharm
- PyTorch版本:1.8.1
💥 项目专栏:【PyTorch深度学习项目实战100例】
一、基于MobileNetv3实现人脸面部表情识别
人脸表情是人类信息交流的重要方式,它所富含的人体行为信息与人的情感状态、精神状态、健康状态等有着极为密切的关联。因此,通过对于人脸表情的识别可以获得很多有价值的信息,从而分析人类的心理活动和精神状态,并为各种机器视觉和人工智能控制系统的应用提供了解决方案。
所以本项目在研究人脸面部表情识别过程中,借助人工智能算法的优势,开展基于深度神经网络的图像分类实验。借助MobileNetv3模型进行迁移学习,经迭代100次后分类准确率达到90.54%。
二、数据集介绍
数据集介绍
128K张MMA面部表情图像数据集
MMAFEDB包含用于培训,验证和测试的目录。
每个目录包含对应于七个面部表情类别的七个子目录。
数据说明:
- angry-愤怒
- disgust-厌恶
- fear-恐惧
- happy-快乐
- neutral-中性
- sad-悲伤
- surprise-惊讶
数据集下载链接:
https://www.heywhale.com/mw/dataset/5ee06333b772f5002d731821/content
三、MobileNetV3模型

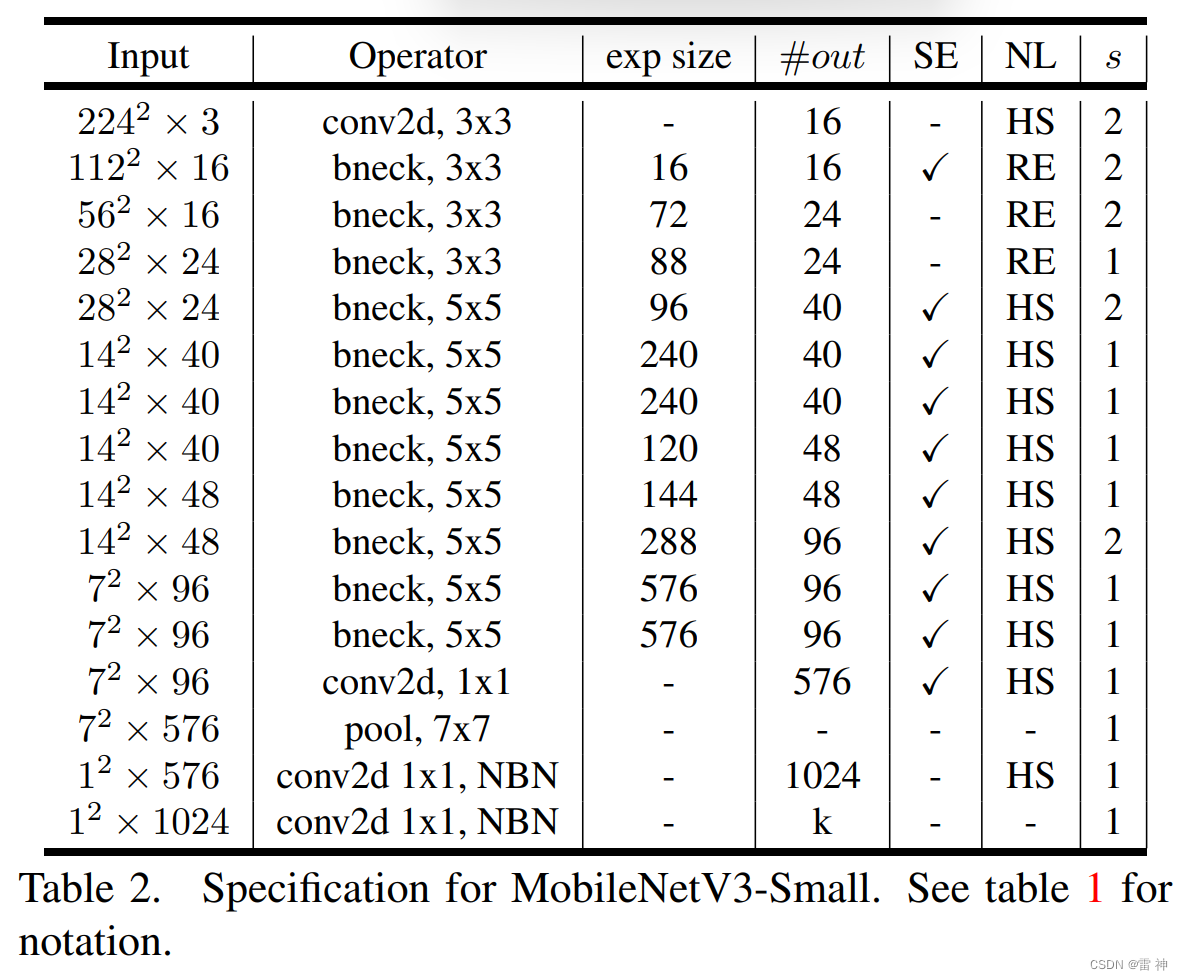
相对重量级网络而言,轻量级网络的特点是参数少、计算量小、推理时间短。更适用于存储空间和功耗受限的场景,例如移动端嵌入式设备等边缘计算设备。因此轻量级网络受到了广泛的关注,其中MobileNet可谓是其中的佼佼者。MobileNetV3经过了V1和V2前两代的积累,性能和速度都表现优异,受到学术界和工业界的追捧,无疑是轻量级网络的“抗把子“。MobileNetV3 参数是由NAS(network architecture search)搜索获取的,又继承的V1和V2的一些实用成果,并引人SE通道注意力机制,可谓集大成者。
四、加载预训练模型
这里我们加载pytorch中已经训练好的GoogLeNet模型,需要一定时间下载训练好的模型权重。
由于预训练的模型与我们的任务需要不一样,所以需要我们将要修改最后一层的全连接层,将输出维度修改为我们的任务要求中的四分类。
但是需要注意需要冻结其它层的参数,防止训练过程中将其进行改动,然后进行训练微调最后一层即可。
# 5.加载MobileNetv3模型
model = torchvision.models.mobilenet_v3_small(pretrained=True) # 加载预训练好的MobileNetv3模型
# 冻结模型参数
for param in model.parameters():
param.requires_grad = False
# 修改最后一层的全连接层
model.classifier[3] = nn.Linear(model.classifier[3].in_features, 7)
# 将模型加载到cpu中
model = model.to('cpu')
# criterion = nn.CrossEntropyLoss() # 损失函数
criterion = MyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # 优化器
五、自定义损失函数
由于我们的任务为多分类问题,所以损失函数需要使用为交叉熵损失函数(Cross Entropy),但是这里我们没有采用框架自带的,而是自己实现了一个损失函数,其实功能是一样的,这里只是为了熟悉如何进行自定义损失函数,虽说大多数情况下,框架自带的损失函数能够满足我们的需求,但是对于一些特定任务,是无法满足的需要我们进行自定义。
定义函数需要继承 nn.Module 子类,然后定义好参数还有所需的变量,在forward中进行编写计算损失函数的过程,然后PyTorch会自动的计算反向传播需要的梯度,不需我们自己进行计算。
# 自定义损失函数,需要在forward中定义过程
class MyLoss(nn.Module):
def __init__(self):
super(MyLoss, self).__init__()
# 参数为传入的预测值和真实值,返回所有样本的损失值,自己只需定义计算过程,反向传播PyTroch会自动记录,最好用PyTorch进行计算
def forward(self, pred, label):
# pred:[32, 4] label:[32, 1] 第一维度是样本数
exp = torch.exp(pred)
tmp1 = exp.gather(1, label.unsqueeze(-1)).squeeze()
tmp2 = exp.sum(1)
softmax = tmp1 / tmp2
log = -torch.log(softmax)
return log.mean()
六、训练过程
train epoch[1/10] loss:1.931: 100%|████████████████████████████████████████████████████| 27/27 [00:28<00:00, 1.06s/it]
【EPOCH: 】1
训练损失为55.50532126426697
训练精度为23.61%
train epoch[2/10] loss:2.162: 100%|████████████████████████████████████████████████████| 27/27 [00:28<00:00, 1.06s/it]
【EPOCH: 】2
训练损失为50.870723247528076
训练精度为29.49%
train epoch[3/10] loss:1.760: 100%|████████████████████████████████████████████████████| 27/27 [00:36<00:00, 1.36s/it]
【EPOCH: 】3
训练损失为51.71602666378021
训练精度为29.61%
train epoch[4/10] loss:2.810: 100%|████████████████████████████████████████████████████| 27/27 [00:35<00:00, 1.33s/it]
【EPOCH: 】4
训练损失为52.830843567848206
训练精度为30.78%
train epoch[5/10] loss:1.724: 100%|████████████████████████████████████████████████████| 27/27 [00:39<00:00, 1.46s/it]
【EPOCH: 】5
训练损失为50.44184374809265
训练精度为32.19%
train epoch[6/10] loss:2.046: 100%|████████████████████████████████████████████████████| 27/27 [00:33<00:00, 1.26s/it]
【EPOCH: 】6
训练损失为49.46258223056793
训练精度为31.72%
train epoch[7/10] loss:1.607: 100%|████████████████████████████████████████████████████| 27/27 [00:29<00:00, 1.08s/it]
【EPOCH: 】7
训练损失为53.17816519737244
训练精度为29.84%
train epoch[8/10] loss:1.872: 100%|████████████████████████████████████████████████████| 27/27 [00:28<00:00, 1.06s/it]
【EPOCH: 】8
训练损失为54.47881722450256
训练精度为29.14%
train epoch[9/10] loss:1.677: 100%|████████████████████████████████████████████████████| 27/27 [00:26<00:00, 1.00it/s]
【EPOCH: 】9
训练损失为52.271769404411316
训练精度为30.78%
train epoch[10/10] loss:2.269: 100%|███████████████████████████████████████████████████| 27/27 [00:29<00:00, 1.09s/it]
【EPOCH: 】10
训练损失为52.047794222831726
训练精度为31.84%
Finished Training
完整源码
import torchvision
from torch import nn
import numpy as np
import os
import json
import pickle
import torch
import torch.optim as optim
import torch.nn.functional as F
from torchvision import transforms, datasets
import torchvision.models as models
from tqdm import tqdm
from PIL import Image
import matplotlib.pyplot as plt
epochs = 10
lr = 0.03
batch_size = 32
image_path = './data'
save_path = './checkpoints/best_model.pkl'
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 1.数据转换
data_transform = {
# 训练中的数据增强和归一化
'train': transforms.Compose([
transforms.RandomResizedCrop(224), # 随机裁剪
transforms.RandomHorizontalFlip(), # 左右翻转
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 均值方差归一化
])
}
# 2.形成训练集
train_dataset = datasets.ImageFolder(root=os.path.join(image_path),
transform=data_transform['train'])
# 3.形成迭代器
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size,
True)
print('using {} images for training.'.format(len(train_dataset)))
# 4.建立分类标签与索引的关系
cloth_list = train_dataset.class_to_idx
class_dict = {}
for key, val in cloth_list.items():
class_dict[val] = key
with open('class_dict.pk', 'wb') as f:
pickle.dump(class_dict, f)
# 自定义损失函数,需要在forward中定义过程
class MyLoss(nn.Module):
def __init__(self):
super(MyLoss, self).__init__()
# 参数为传入的预测值和真实值,返回所有样本的损失值,自己只需定义计算过程,反向传播PyTroch会自动记录,最好用PyTorch进行计算
def forward(self, pred, label):
# pred:[32, 4] label:[32, 1] 第一维度是样本数
exp = torch.exp(pred)
tmp1 = exp.gather(1, label.unsqueeze(-1)).squeeze()
tmp2 = exp.sum(1)
softmax = tmp1 / tmp2
log = -torch.log(softmax)
return log.mean()
# 5.加载MobileNetv3模型
model = torchvision.models.mobilenet_v3_small(pretrained=True) # 加载预训练好的MobileNetv3模型
# 冻结模型参数
for param in model.parameters():
param.requires_grad = False
# 修改最后一层的全连接层
model.classifier[3] = nn.Linear(model.classifier[3].in_features, 7)
# 将模型加载到cpu中
model = model.to('cpu')
# criterion = nn.CrossEntropyLoss() # 损失函数
criterion = MyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # 优化器
# 6.模型训练
best_acc = 0 # 最优精确率
best_model = None # 最优模型参数
for epoch in range(epochs):
model.train()
running_loss = 0 # 损失
epoch_acc = 0 # 每个epoch的准确率
epoch_acc_count = 0 # 每个epoch训练的样本数
train_count = 0 # 用于计算总的样本数,方便求准确率
train_bar = tqdm(train_loader)
for data in train_bar:
images, labels = data
optimizer.zero_grad()
output = model(images.to(device))
loss = criterion(output, labels.to(device))
loss.backward()
optimizer.step()
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# 计算每个epoch正确的个数
epoch_acc_count += (output.argmax(axis=1) == labels.view(-1)).sum()
train_count += len(images)
# 每个epoch对应的准确率
epoch_acc = epoch_acc_count / train_count
# 打印信息
print("【EPOCH: 】%s" % str(epoch + 1))
print("训练损失为%s" % str(running_loss))
print("训练精度为%s" % (str(epoch_acc.item() * 100)[:5]) + '%')
if epoch_acc > best_acc:
best_acc = epoch_acc
best_model = model.state_dict()
# 在训练结束保存最优的模型参数
if epoch == epochs - 1:
# 保存模型
torch.save(best_model, save_path)
print('Finished Training')
# 加载索引与标签映射字典
with open('class_dict.pk', 'rb') as f:
class_dict = pickle.load(f)
# 数据变换
data_transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor()])
# 图片路径
img_path = r'./data/test.jpg'
# 打开图像
img = Image.open(img_path)
# 对图像进行变换
img = data_transform(img)
plt.imshow(img.permute(1,2,0))
plt.show()
# 将图像升维,增加batch_size维度
img = torch.unsqueeze(img, dim=0)
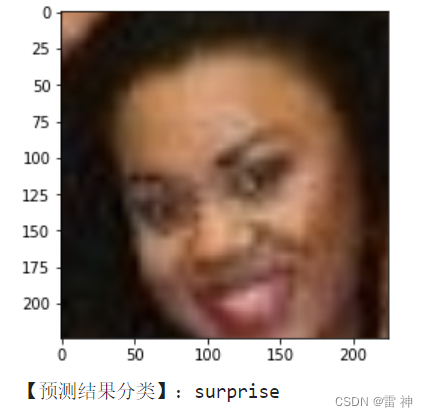
# 获取预测结果
pred = class_dict[model(img).argmax(axis=1).item()]
print('【预测结果分类】:%s' % pred)