第二章 计算机系统结构基础
在三台不同指令系统的计算机上运行同一程序P时,A机需要执行 1.0 × 1 0 8 1.0\times10^8 1.0×108条指令,B机需要执行 2.0 × 1 0 8 2.0\times 10^8 2.0×108条指令,C机需要执行 4.0 × 1 0 8 4.0\times10^8 4.0×108条指令,但实际执行时间都是10秒,请分别计算这三台机器在实行程序P时的实际运行速度,以MIPS为单位。这三台计算机在运行程序P时,哪台性能最高?为什么?(2019、2020、2021真题,仅改动幂次)
解:
A 为 10MIPS,B 为 20MIPS,C 为 40MIPS。
三台机器在运行程序P时,性能一致,因为用时相同。
对某处理器进行功耗测试,得到如下数据:时钟不翻转,电压1. 05V时,电流为500mA;时钟频率为1GHz,电压1.1V时,电流为2500mA。请计算此处理器的静态功耗以及500MHz下的总功耗。(2019、2020、2021真题,仅改动数据)
解:
总功耗:
P
t
o
t
a
l
=
P
s
w
i
t
c
h
+
P
s
h
o
r
t
+
P
l
e
a
k
a
g
e
P_{total} = P_{switch} + P_{short} + P_{leakage}
Ptotal=Pswitch+Pshort+Pleakage
静态功耗:
P
s
t
a
t
i
c
=
P
l
e
a
k
a
g
e
P_{static}=P_{leakage}
Pstatic=Pleakage,电路作为纯电阻电路时的功耗。
动态功耗:
P
d
y
n
a
m
i
c
=
P
s
w
i
t
c
h
+
P
s
h
o
r
t
P_{dynamic} = P_{switch} + P_{short}
Pdynamic=Pswitch+Pshort其中主要成分为
P
s
w
i
t
c
h
=
C
o
u
t
V
d
d
2
f
c
l
k
/
2
P_{switch}=C_{out}V_{dd}^2f_{clk}/2
Pswitch=CoutVdd2fclk/2。动态功耗可近似看作与电压的平方、时钟频率成正比。
1.1V下的静态功耗:
P
s
t
a
t
i
c
=
U
2
/
R
=
(
1.1
V
)
2
/
(
1.05
V
/
0.5
A
)
=
0.576
W
P_{static} = U^2/R = (1.1V)^2/(1.05V / 0.5A) = 0.576W
Pstatic=U2/R=(1.1V)2/(1.05V/0.5A)=0.576W
1.1V,1GHz的动态功耗:
P
d
y
n
a
m
i
c
=
P
t
o
t
a
l
−
P
s
t
a
t
i
c
=
1.1
V
×
2.5
A
−
0.576
W
=
2.174
W
P_{dynamic}=P_{total}-P_{static}=1.1V \times 2.5A - 0.576W = 2.174W
Pdynamic=Ptotal−Pstatic=1.1V×2.5A−0.576W=2.174W
1.1V,0.5GHz 动态功耗:
2.174
W
∗
(
0.5
G
H
z
/
1
G
H
z
)
=
1.087
W
2.174W*(0.5GHz/1GHz)=1.087W
2.174W∗(0.5GHz/1GHz)=1.087W
1.1V,0.5GHz总功耗:
1.087
W
+
0.576
W
=
1.663
W
1.087W+0.576W=1.663W
1.087W+0.576W=1.663W
如果要给标量处理器增加向量运算部件,并且假定向量模式的运算速度时标量模式的8倍,这里把程序中可向量化部分运算量站总运算量的百分比成为向量化百分比。(1)画出一张图来表示加速比和向量化百分比的关系,X轴为向量化百分比,Y轴为加速比。(2)向量化百分比为多少时,加速比能达到2?当加速比达到2时,向量模式运行时间占总运行时间的百分之多少?(3)假设程序的向量化百分比为70%,如果需要继续提升处理器的性能,一种方法是增加硬件成本将向量部件的速度提高一倍,另一种方法是通过改进编译器来提高程序中向量模式的百分比,那么需要提升多少向量化百分比才能得到与向量部件运算速度提高一倍相同的性能?你推荐哪一种方案?(2021复习题)
解:
(1)加速比 y 与向量化比例 x 之间的关系是:
y
=
1
(
1
−
x
)
+
x
/
8
=
8
8
−
7
x
(
a
)
y = \frac{1}{(1-x) + x/8} = \frac{8}{8-7x} (a)
y=(1−x)+x/81=8−7x8(a)
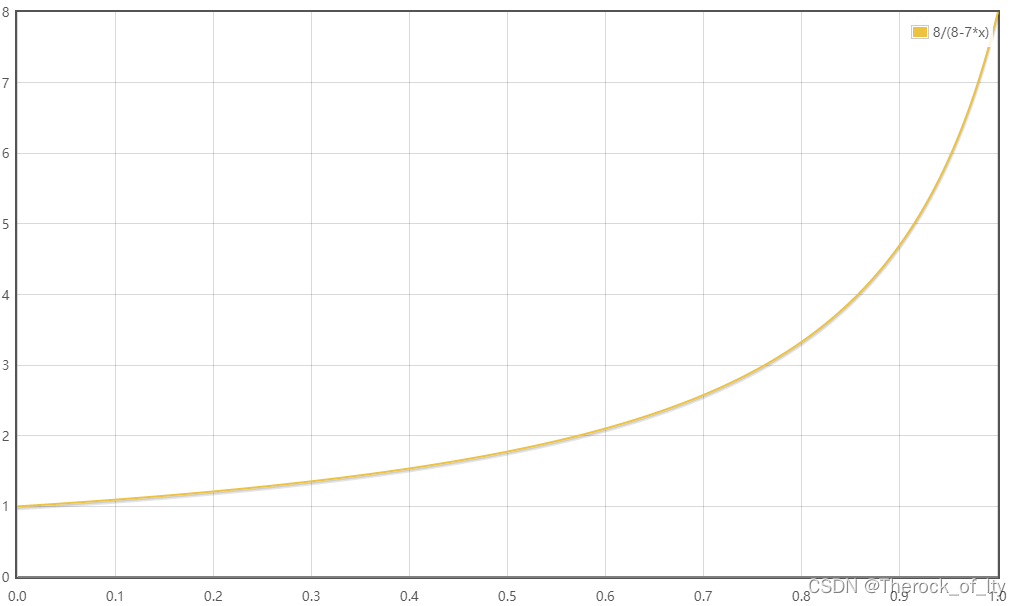
(2)在式
(
a
)
(a)
(a)中令
y
=
2
y=2
y=2,可解得
x
=
4
/
7
≈
57.14
%
x=4/7≈57.14\%
x=4/7≈57.14%。
向量模式运行时间占总时间的比例是
4
/
7
×
1
/
8
3
/
7
+
4
/
7
×
1
/
8
=
1
/
7
≈
14.29
%
\frac{4/7 \times 1/8}{3/7 + 4/7 \times 1/8}=1/7 ≈14.29\%
3/7+4/7×1/84/7×1/8=1/7≈14.29%
(3)硬件方法:
y
=
1
(
1
−
x
)
+
x
/
16
=
16
16
−
15
x
(
b
)
y = \frac{1}{(1-x) + x/16} = \frac{16}{16-15x} (b)
y=(1−x)+x/161=16−15x16(b) 取
x
=
0.7
x=0.7
x=0.7,得
y
=
2.91
y=2.91
y=2.91
软件方法:令
(
a
)
(a)
(a)中
y
=
2.91
y=2.91
y=2.91,解得
x
=
0.75
x=0.75
x=0.75。
于是推荐软件方法。
第三章 二进制与逻辑电路
定点数的表示:(1)分别给出64位定点原码和补码所表示的数的范围(2)在32位顶点补码表示中,0x80000000表示什么数?(3)在32位顶点补码表示中,0xffffffff表示什么数?(2019、2020、2021真题)
解:
(1)原码:最高位是符号位,
[
−
(
2
63
−
1
)
,
2
63
−
1
]
[-(2^{63} -1), 2^{63}-1]
[−(263−1),263−1],有
+
0
+0
+0和
−
0
-0
−0之分。
补码:最高位是符号位,
[
−
2
63
,
2
63
−
1
]
[-2^{63}, 2^{63}-1]
[−263,263−1],没有
−
0
-0
−0。
(2)
−
2
31
-2^{31}
−231
(3)
−
1
-1
−1
画出$e = a&b | c&d $的晶体管级电路图(2019真题)
解:
a
&
b
∣
c
&
d
=
a
&
b
∣
c
&
d
‾
‾
=
a
&
b
‾
&
c
&
d
‾
‾
a\&b | c\&d = \overline{\overline{a\&b | c\&d}} = \overline{\overline{a\&b} \& \overline{c\&d}}
a&b∣c&d=a&b∣c&d=a&b&c&d 两层与非门的组合。

需要注意的是,P管必须接电,N管必须接地。
画出$e = a|b & c|d $的晶体管级电路图(2020真题)
解:
a
∣
b
&
c
∣
d
=
a
∣
b
&
c
∣
d
‾
‾
=
a
∣
b
‾
∣
c
∣
d
‾
‾
a|b \& c|d = \overline{\overline{a|b \& c|d}} = \overline{\overline{a|b} | \overline{c|d}}
a∣b&c∣d=a∣b&c∣d=a∣b∣c∣d 两层或非门的组合。

画出$e = a|b & c&d $的晶体管级电路图(2021真题)
解:
a
∣
b
&
c
&
d
=
a
∣
b
&
c
&
d
‾
‾
=
a
∣
b
‾
∣
c
&
d
‾
‾
a|b \& c\&d = \overline{\overline{a|b \& c\&d}} = \overline{\overline{a|b} | \overline{c\&d}}
a∣b&c&d=a∣b&c&d=a∣b∣c&d 第一层或非门和与非门,第二层或非门。
计算一个FO4的延迟,假设反相器的输入电容为0.0036pF,平均每个负载连线电容为0.0044pF,翻转延迟为0.023ns,每pF延迟为4.5ns(2019、2021真题,仅改动数字)。
解:
FO4是一个单元驱动相同的四个单元,本题目中指的是反相器。
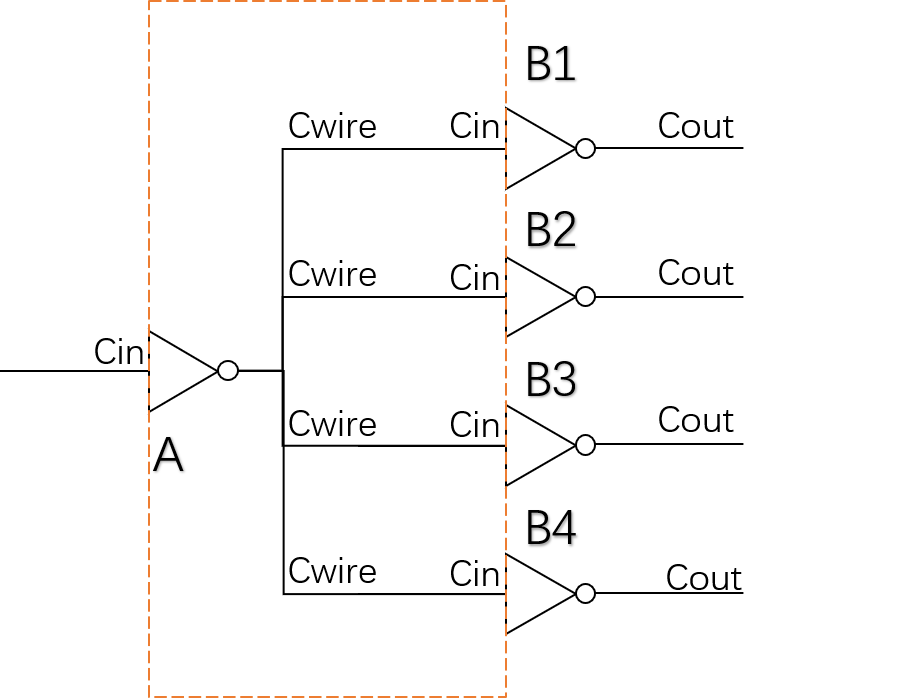
如图,一个反相器驱动四个反相器,电流方向从左到右。
一个单元的延迟,等于单元的本征延迟加上该单元的负载延迟。
图中:
C
i
n
Cin
Cin表示一个单元的输入负载,其意义可直观理解为该器件发生反转所需要充放的电容大小。对应题目中的0.0036pF。
C
w
i
r
e
Cwire
Cwire表示每条连线的负载,其意义可直观理解为信号在连线上传播所需要充放的电容大小。对应题目中的0.044pF。
C
o
u
t
Cout
Cout表示一个单元的输出负载,其意义可直观理解为它所驱动的全部器件的输入负载以及连线负载之和。
题目要求计算器件A的延迟。考虑如下过程:
1)A的输入信号开始发生变化。变化需要的时间为
(
C
w
i
r
e
+
C
i
n
)
∗
X
=
(
0.0044
p
F
+
0.0036
p
F
)
∗
X
(Cwire+Cin) * X = (0.0044pF + 0.0036pF) * X
(Cwire+Cin)∗X=(0.0044pF+0.0036pF)∗X,其中
X
X
X为A的上一级驱动器件对每pF的延迟。该延迟包含在上一级器件的负载延迟中,故不被算入A的延迟计算。
2)A的电容完成充/放电后,发生反转。用时
0.023
n
s
0.023ns
0.023ns。
3)A反转完成,驱动后续线路。对线路充/放电的用时
4
∗
(
C
w
i
r
e
∗
4.5
n
s
/
p
F
)
=
4
∗
(
0.0044
p
F
∗
4.5
n
s
/
p
F
)
4*(Cwire * 4.5ns/pF) = 4*(0.0044pF * 4.5ns/pF)
4∗(Cwire∗4.5ns/pF)=4∗(0.0044pF∗4.5ns/pF)
4) A继续驱动后续器件,给下一级器件的电容充/放电。用时
4
∗
(
C
i
n
∗
4.5
n
s
/
p
F
)
=
4
∗
(
0.0036
p
F
∗
4.5
n
s
/
p
F
)
4*(Cin * 4.5ns/pF) = 4*(0.0036pF * 4.5ns/pF)
4∗(Cin∗4.5ns/pF)=4∗(0.0036pF∗4.5ns/pF)
5)B的完成充/放电后,发生反转。用时
0.023
n
s
0.023ns
0.023ns。该延迟包含在B器件的本征延迟中,故不被算入A的延迟计算。
6)B反转完成,驱动后续线路。对输出负载的用时
C
o
u
t
∗
Y
Cout * Y
Cout∗Y。
综上,器件A的延迟包括2)3)4),总延迟
0.023
n
s
+
4
∗
(
(
0.0036
p
F
+
0.0044
p
F
)
∗
4.5
n
s
/
p
F
)
=
0.167
n
s
0.023ns + 4*((0.0036pF + 0.0044pF) * 4.5ns/pF)= 0.167ns
0.023ns+4∗((0.0036pF+0.0044pF)∗4.5ns/pF)=0.167ns
第四章 指令系统结构
假设在指令系统设计中需要考虑两种条件转移指令的设计方法,方法如下:(1)CPU A:先通过一条比较指令设置条件码A,再用一条分支指令检测条件码。(2)CPU B:比较操作包含在分支指令中。
两种CPU中,条件转移指令都需要两个时钟周期,所有其他指令都需要一个时钟周期。在CPU A中,程序的全部指令的25%是条件转移指令,因为每次条件转移都需要一次比较,于是25%是比较指令。因为CPU A不需要在转移中包含分支,故时钟频率是B机的1.2倍。比较两种CPU的性能。
解:
假设 CPU A 总指令数为
x
x
x,根据题意,转移指令有
0.25
x
0.25x
0.25x,条件码指令
0.25
x
0.25x
0.25x,其它指
令
0.5
x
0.5x
0.5x,因此 A 执行周期数
2
∗
0.25
x
+
0.75
x
=
1.25
x
2*0.25x+0.75x=1.25x
2∗0.25x+0.75x=1.25x。
可得 CPU B 总指令数为
0.75
x
0.75x
0.75x,其中转移指令
0.25
x
0.25x
0.25x,其它指令
0.5
x
0.5x
0.5x。
B 执行周期数
2
∗
0.25
x
+
0.5
x
=
1
x
2*0.25x+0.5x=1x
2∗0.25x+0.5x=1x。
当 CPU A 频率为 1.2 倍时,性能是 CPU B 的
1.2
/
1.25
=
0.96
1.2/1.25=0.96
1.2/1.25=0.96 倍
当 CPU A 频率为 1.1 倍时,性能是 CPU
B
的
1.1
/
1.25
=
0.88
B 的 1.1/1.25=0.88
B的1.1/1.25=0.88 倍
因此 CPU A 两种情况下都差。
第五章 静态流水线
流水线指令相关的类型(2020真题)
1)数据相关:使用同一个寄存器引起的相关
如:RAW写后读真相关;WAW写后写输出相关;WAR读后写反相关
2)控制相关:与PC有关的相关
如:转移指令
3)结构相关:资源冲突
如:多条指令同时使用一个功能部件
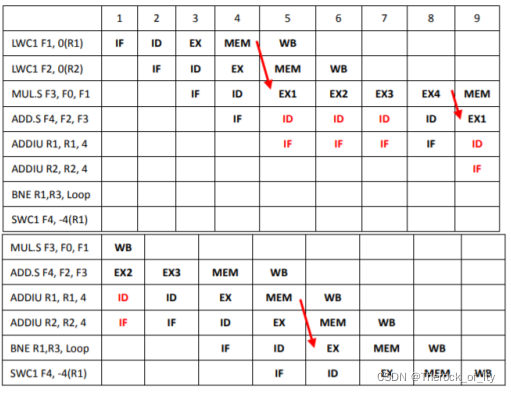
对于浮点向量运算X(i)=a×X(i)+Y(i),假设X和Y的首地址分别存在定点寄存器R1和R2中,a的值存在浮点寄存器F0中。(1)试写出对应的MIPS汇编代码。(2)假设处理提为5.16图所示的单发射5级流水线(IF/ID/EX/MEM/WB)结构,功能部件足够,Load、Store操作和整数操作都花费1个时钟周期,浮点加法操作为3个周期,浮点乘法操作为4个周期。给出第一个循环所有指令的流水线时空图。(2021复习题)
(1)MIPS代码示例:
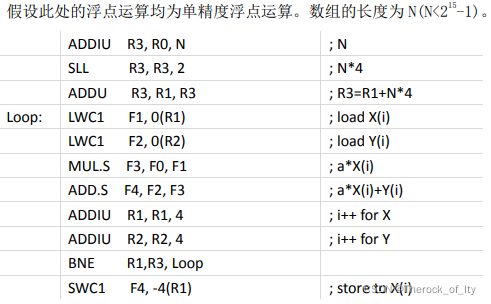
(2)流水线有EX到ID、MEM到ID、MEM到EX的前递
假定某RISC处理器为标准的单发射5级流水(IF/ID/EX/MEM/WB)结构。如下代码在上执行:
Loop: LD R1,0(R2) #从地址0+R2处读入R1
DADDI R1,R1,$4 #R1= R1+4
SD 0(R2),R1 #将R1存入地址0+R2处
DADDI R2,R2,$4 #R2= R2+4
DSUB R4,R3,R2 #R4=R3-R2
BNEZ R4,Loop #R4不等于0时跳转到Loop
NOP
已知知R3的初值为R2+400。
1)不使用旁路硬件,但在同一个周期内寄存器的读和写能进行旁路,分支预测采用not taken策略,如果猜测错误则在转移指令指令执行(EX)后刷新(flushing) 流水线上的错误指令,画出这个指令序列在RISC流水线上执行的时序,计算执行这个循环需要多少个时钟周期。
解:
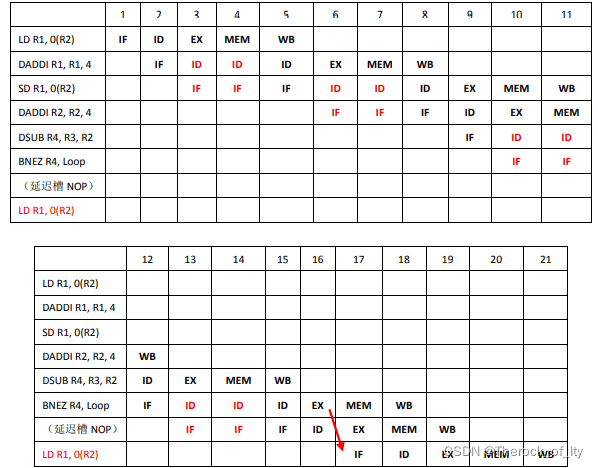
不使用旁路,但是同一周期内寄存器读和写可以旁路,这意味着存在WB到ID的前递。
如DADDI R1,R1,$4指令,如果完全无旁路,第6拍应该仍然处于ID阶段,第7拍才能开始EX。
采用no taken,前99次循环都是预测失败,每个循环16个周期。最后一个循环预测正确,但是延迟槽中指令到第19拍才写回,故总计
16
∗
99
+
19
=
1603
16*99+19=1603
16∗99+19=1603个时钟周期。
2)使用旁路硬件,采用taken策略进行分支预测,如果猜测错误则在转移指令指令执行(EX)后刷新(flushing) 流水线上的错误指令,画出这个指令序列在RISC.上执行的序列,并计算执行这个循环需要多少个时钟周期。
解:
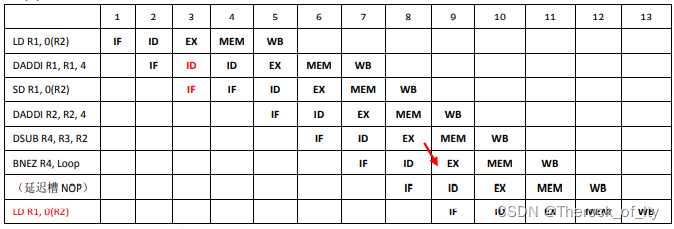
有前递,从MEM取回数据可以直接送至ID。
预测taken,前99次预测正确,一次循环8拍。最后一个循环等待延迟槽指令WB,12拍,故总计
8
∗
99
+
12
=
804
8*99 + 12 = 804
8∗99+12=804拍。
3)假设RISC流水线带有单拍的分支延迟和前递或旁路硬件,对包括延迟槽在内的指令序列进行调度,可以重排指令序列,并修改某些指令的操作数,但不能改变指令的数目和采用别的指令,画出该流水线的时序图,并计算整个循环需要的时钟周期数。
解:
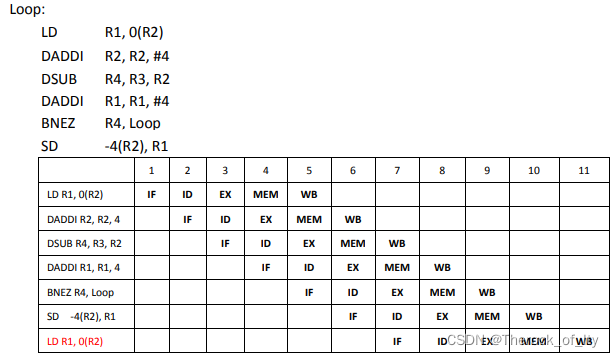
前99次循环,执行一个循环需要6拍。最后一次循环完整执行完需要10拍。
整个循环共计:
6
∗
99
+
10
=
604
6*99+10=604
6∗99+10=604 时钟周期。
第六章 动态流水线
解释保留站、重命名寄存器和ROB的作用。
保留站:指令有序进入保留站,在保留站内等待相关被解决后乱序发射至功能部件进行执行。
重命名寄存器:通过对同一个逻辑寄存器重命名成多个不同的物理寄存器,可以解决 WAW
相关,并且避免伪 RAW 相关。
Reorder buffer:指令不论何时写回寄存器,它在 reoder buffer 中退出的顺序必须符合程
序序。这保证了乱序执行下,中断能有精确现场。
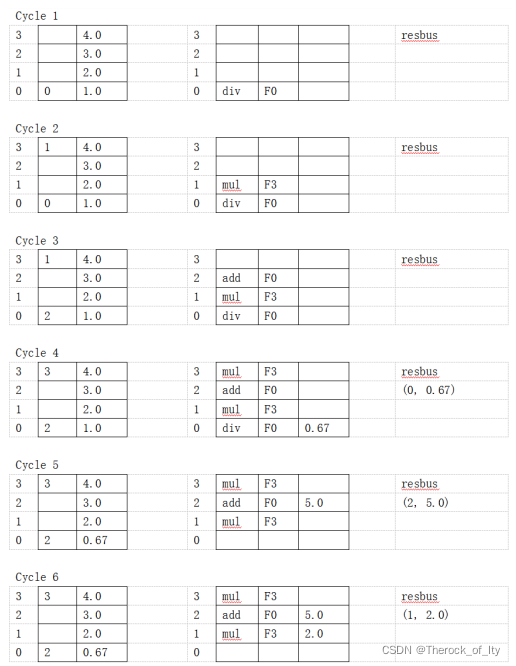
假设一个如图所示支持精确例外处理的浮点流水线,流水线分成发射、执行并写回以及提交3个阶段,其中浮点加法部件延迟为2拍,乘除法为3拍,请给出6拍内每一拍的寄存器以及结果总线值的变化。(2020真题)
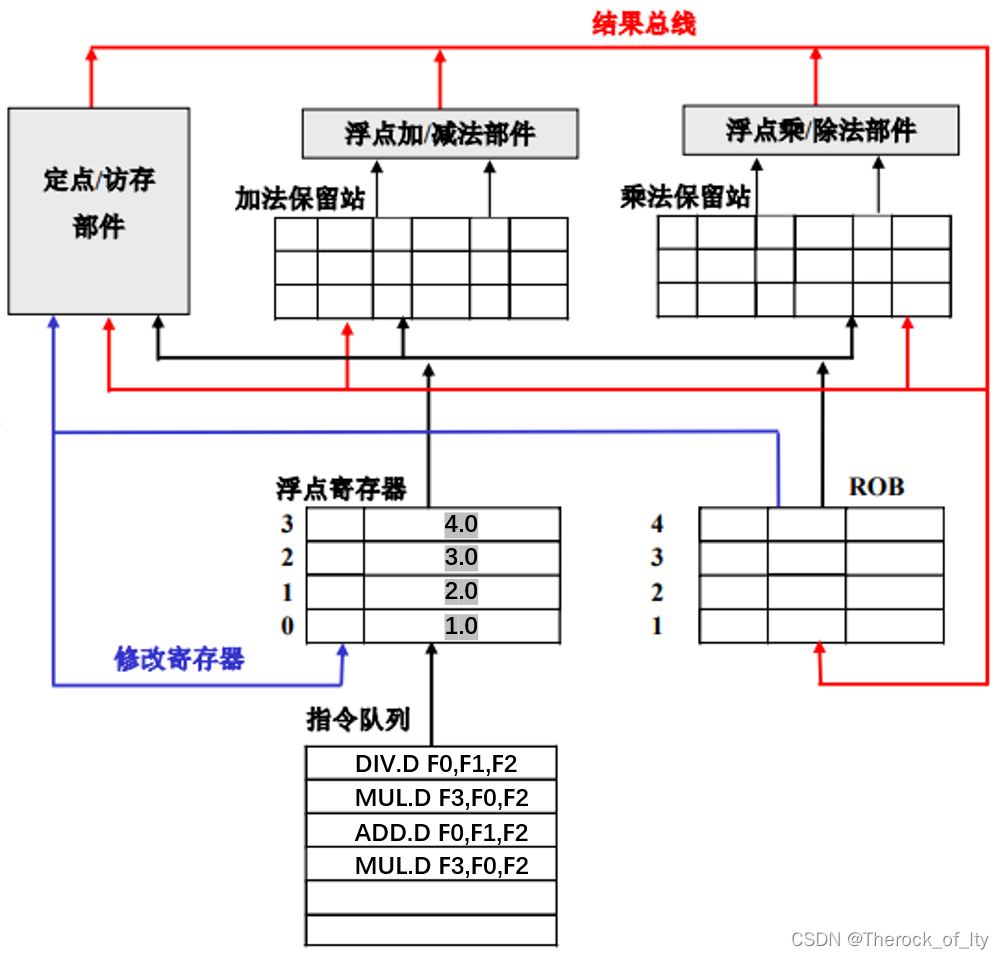
| 指令 | 发射 | 执行并写回 | 提交 |
|---|---|---|---|
| DIV.D | 1 | 2-4 | 5 |
| MUL.D | 2 | 4-6 | 7 |
| ADD.D | 3 | 4-5 | 8 |
| MUL.D | 4 | 5-7 | 9 |
说明:计算部件输出的结果,可以沿着结果总线前递至保留站。于是第4拍DIV.D写回的数据,可以直接填到乘法保留站中的MUL.D指令,并开始执行。
总线由二元数组组成,ROB的index以及写回值。
提交时,修改寄存器的值。并且,ROB中的指令不可以乱序提交。
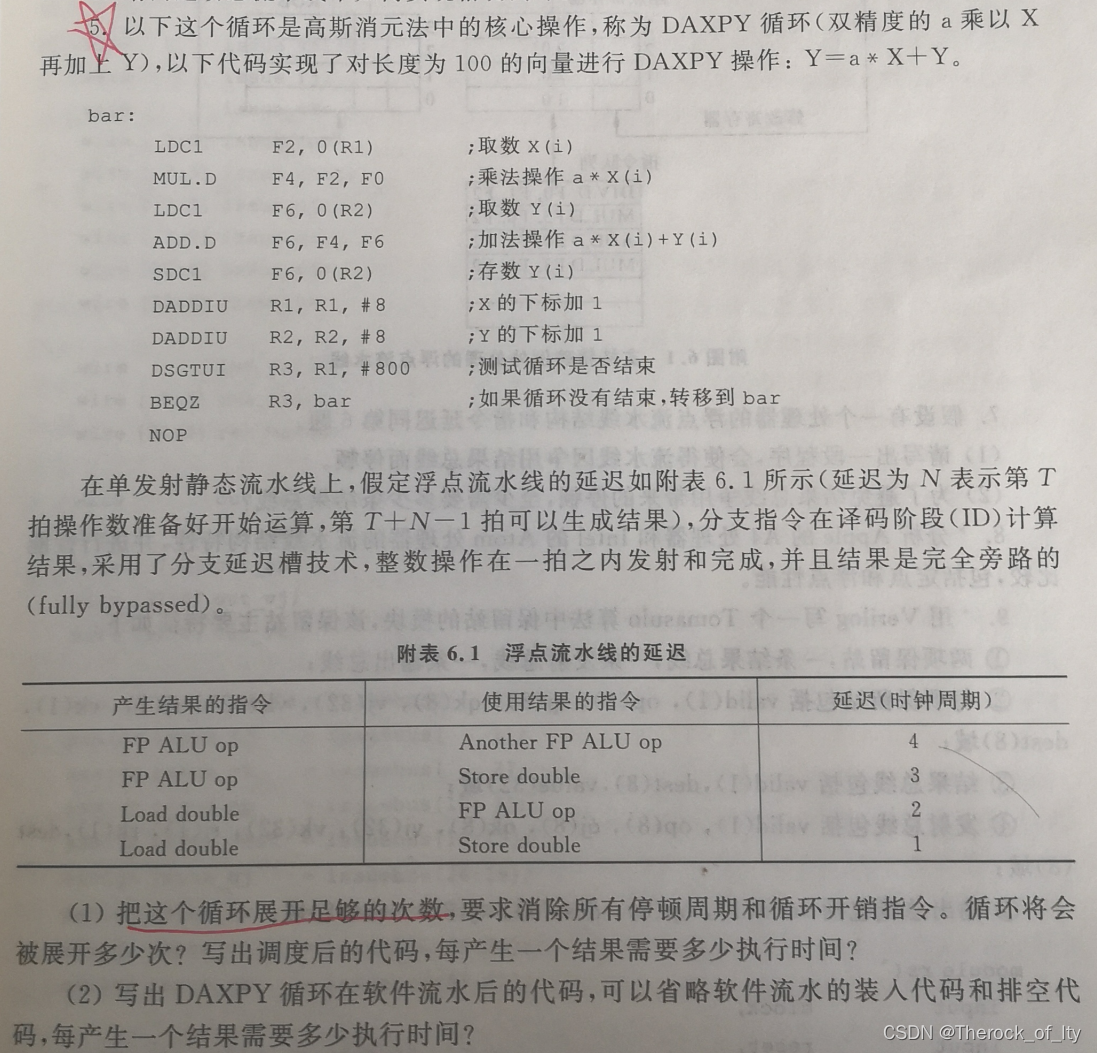
DAXPY循环。对长度100的向量进行双精度的a乘以X再加上Y的操作(2021真题,给出装入代码,写出主题循环和排空代码,延迟改为3343)。
解:
1)分析依赖:
LDCL F2,0(R1)与MUL.D F4,F2,F0有RAW相关。二者应该隔开1条指令。
MUL.D F4,F2,F0与ADD.D F6,F4,F6有RAW相关。二者应该隔开3条指令。
LDCL F6,0(R2)与ADD.D F6,F4,F6有RAW相关。二者应该隔开1条指令。
ADD.D F6,F4,F6与SDCL F6,0(R2)有RAW相关。二者应该隔开2条指令。
其他指令都是一拍内完成,不存在流水阻塞。
尝试循环展开两次:
bar:
LDCL F2,0(R1)
LDCL F3,8(R1)
MUL.D F4,F2,F0
MUL.D F5,F3,F0
LDCL F6,0(R2)
LDCL F7,8(R2)
ADD.D F6,F4,F6
ADD.D F7,F5,F7
DADDIU R1,R1,$16
SDCL F6,0(R2)
SDCL F7,8(R2)
DSGTUI R3,R1,$800
BEQZ R3,bar
DADDIU R2,R2,$16
14拍两个,故平均7拍一个。
2)
软件流水基本方法:
- 分析主体循环代码的RAW相关结构。多条RAW依赖链上,没有相互依赖的同一层可以合并为同一层。
- 循环展开对齐,展开次数为RAW相关的层数。
- 加入其他代码,调整重命名寄存器。
- 补充装入与排空代码。

主体代码为1、2、3、4、5,循环展开四次:
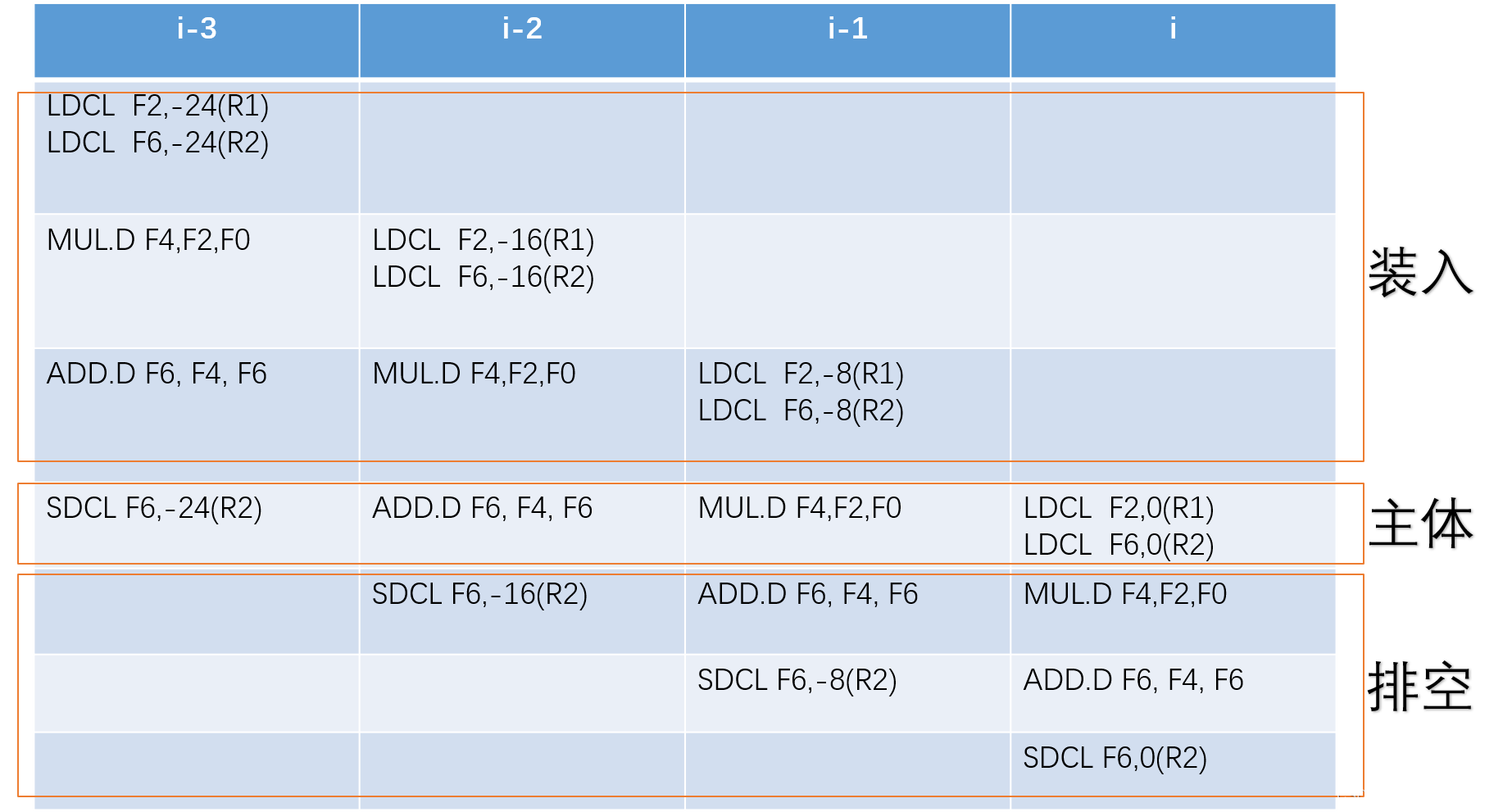
调整代码:
装入代码部分,按i-3,i-2,i-1的顺序执行代码块,应该不会有依赖问题。但是,i-3的装入代码ADD.D 修改F6的值,在主体代码中会使用,但是F6又会被后续的i-2装入代码修改,于是需要重命名寄存器。
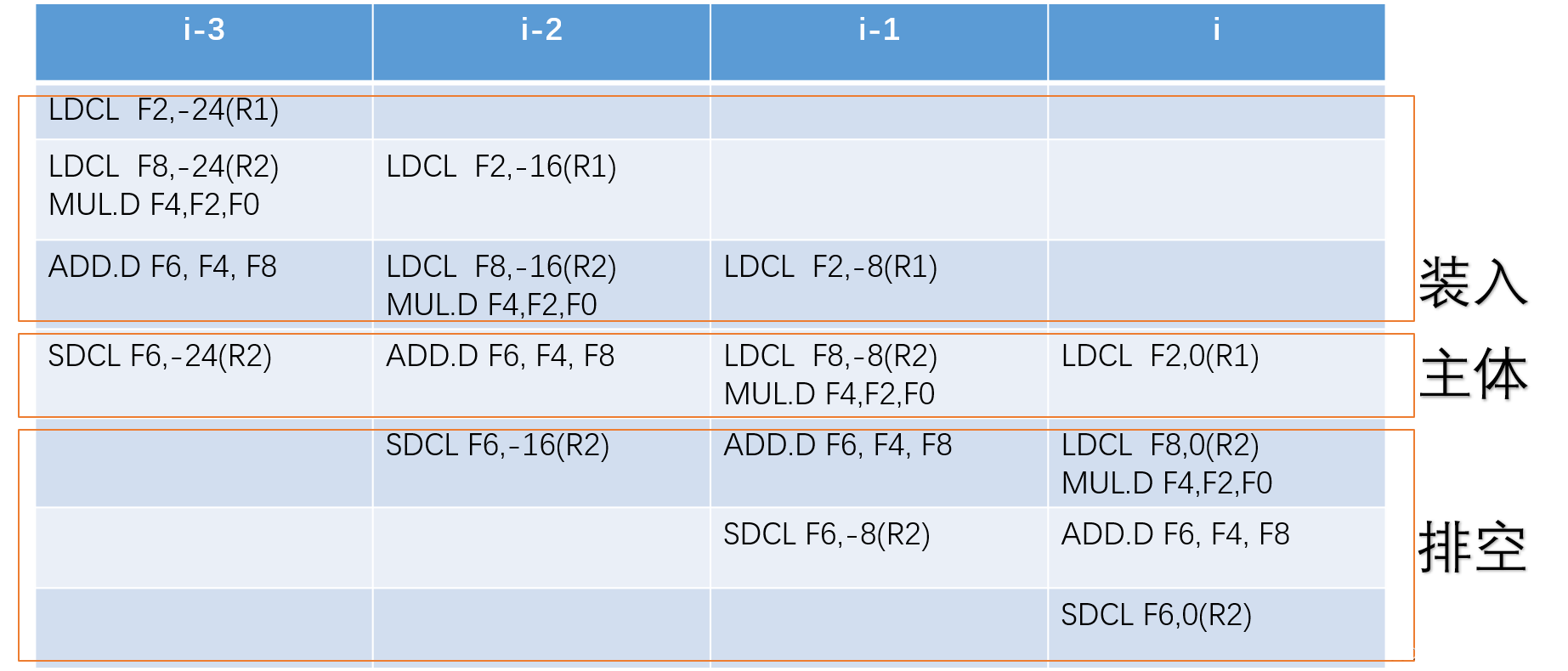
#装入代码
LDCL F2,0(R1)
LDCL F8,0(R2)
MUL.D F4,F2,F0
ADD.D F6,F4,F8
LDCL F2,8(R1)
LDCL F8,8(R2)
MUL.D F4,F2,F0
LDCL F2,16(R1)
DADDIU R1,R1,24
DADDIU R2,R2,24
#主体代码
bar:
SDCL F6,-24(R2)
ADD.D F6,F4,F8
LDCL F8,-8(R2)
MUL.D F4,F2,F0
LDCL F2,0(R1)
DAADIU R1,R1,$8
DSGTUI R3,R1,$800
BEQZ R3,bar
DADDIU R2,R2,$8
#排空代码
SDCL F6,-24(R2)
ADD.D F6,F4,F8
SDCL F6,-16(R2)
LDCL F8,-8(R2)
MUL.D F4,F2,F0
ADD.D F6,F4,F8
SDCL F6,-8(R2)
第七章 多发射数据通路
多发射(2021复习题)

1)循环展开两次:(这题目不和第六章的那个一样吗?)
L:
LDCL F0,0(R1)
LDCL F6,-8(R1)
MUL.D F0,F0,F2
MUL.D F6,F6,F2
LDCL F4,0(R2)
LDCL F8,-8(R2)
ADD.D F0,F0,F4
ADD.D F8,F6,F8
DADDIU R1,R1,$-16
SDCL F0,16(R2)
SDCL F6,8(R2)
BNEZ R1,L
DADDIU R2,R2,$-16
一个周期13拍,平均每个6.5拍。
2)双发射,假设双发射流水线中有彼此独立的一条定点流水线和一条浮点流水线。
由于真相关的两条浮点指令之间需要相隔三拍,于是考虑把循环展开四次:

一个n发射的处理器,流水线情况如下:取指,译码,重命名到物理寄存器后送入发射队列,发射队列乱序发射,功能部件乱序执行,乱序写回物理寄存器,最后顺序提交并释放物理寄存器。已知该处理器有m个逻辑寄存器,i个功能部件(i>n),每条指令从重命名到写回需要t1拍,从重命名到提交需要t2拍。为了能让流水线满负荷工作,最少需要多少个物理寄存器?(2019真题)
解:
最少需要
n
×
t
2
+
m
n\times t_2 + m
n×t2+m个物理寄存器。
每条指令在重命名的时候需要占用一个物理寄存器,每拍有n条指令发射,并且在提交时,重命名的寄存器才会被释放。因此在满载情况下,始终有
n
×
t
2
n\times t_2
n×t2个重命名寄存器。加上t=0时,已经被映射到逻辑寄存器的
m
m
m个寄存器,故最少需要
n
×
t
2
+
m
n\times t_2 + m
n×t2+m个物理寄存器。
第八章 转移猜测
表中是转移猜测的Yeh和Patt分类中根据转移历史表(BHT)和模式历史表(PHT)的不同组合形成的转移猜测种类。PC用来索引BHT表的位数为低6位,索引PHT表的位数为低8位,BHT表每项为9位,请画出SAs转移猜测的结构图,说明其基本原理,并计算该结构使用的存储单元位数。(2019、2020真题)
解:
BHR
Branch History Register,分支历史寄存器,记录了所有满足条件的分支指令历史上m次的转移记录,用来索引PHT表。
GA:Global address BHR,表示全部PC共用同一个寄存器记录历史。
PA:Per address BHR,表示每个PC都单独用一个寄存器记录历史。
SA:Set address BHR,表示PC部分低位相同的分支指令共用同一个寄存器记录历史。
PHT
Pattern History Table,模式历史表,记录该指令的历史跳转记录,来预测这一次是否跳转。通常一个表项是2位饱和计数,00、01表示不跳转,10、11表示跳转。
g:Global address PHT,表示全部PC共用同一个表单,也即只用BHR索引PHT表。
p:Per address PHT,表示每个PC都单独有一个表单,也即用全地址和BHR一起索引PHT表。
s:Per set PHT,表示PC部分低位相同的分支指令共用一个表单,也即用部分地址和BHR一起索引PHT表。


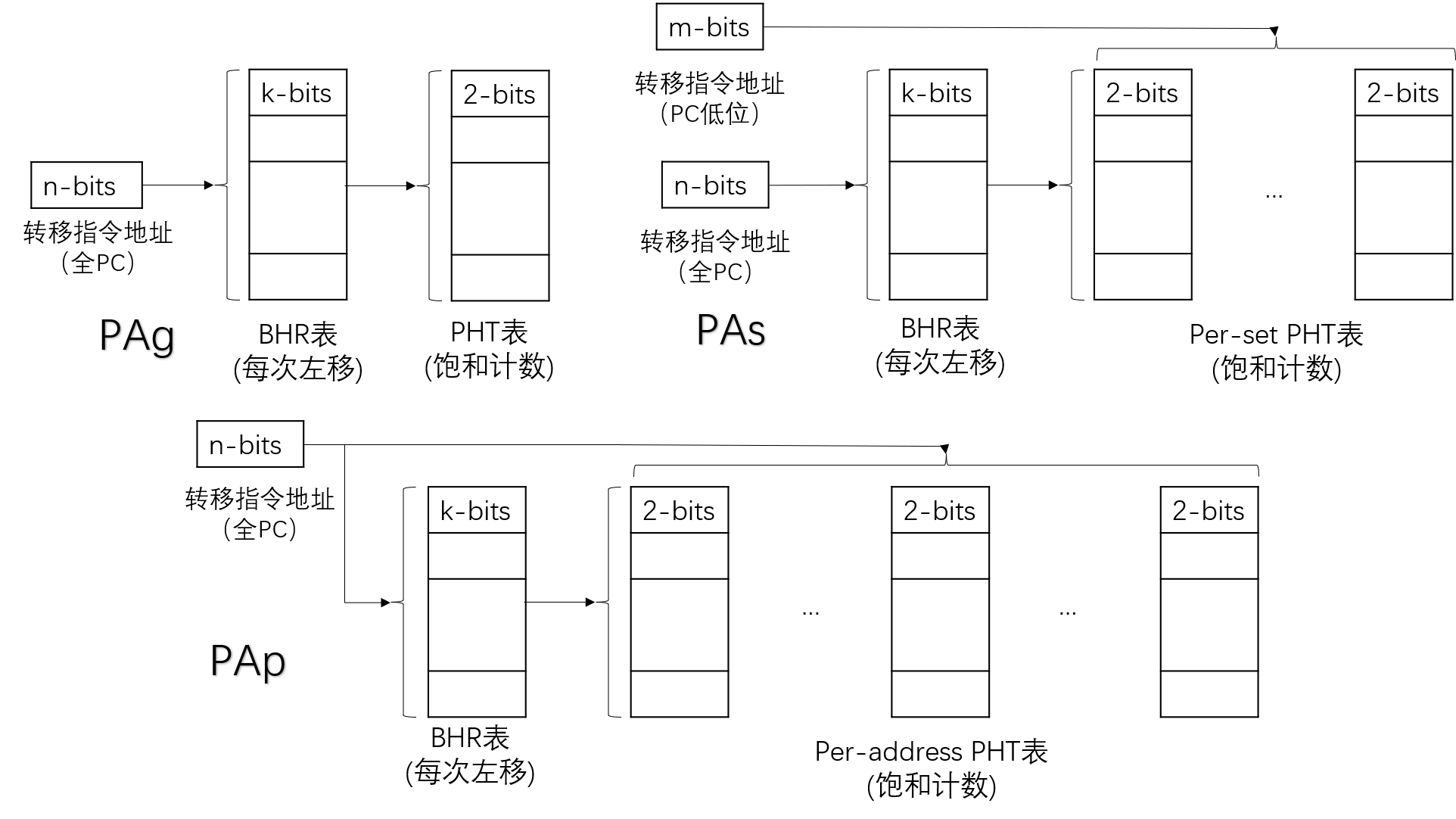
由图示,SAs转移猜测中,BHR表有 2 6 2^6 26项,占用 2 6 × 9 = 576 b 2^6 \times 9 = 576b 26×9=576b。PHT表有 2 8 2^8 28页,每页大小为 2 × 2 9 = 1024 b 2 \times 2^9 = 1024b 2×29=1024b,一共占用 1024 × 2 8 = 262144 b 1024 \times 2^8 = 262144b 1024×28=262144b。合计 262144 + 576 = 262720 b 262144 + 576 = 262720b 262144+576=262720b。
分析:for (i=0;i<10;i++) for(j=0;j<10;j++){…}的分支预测正确率。(2021复习题)
解:
外层循环前9次跳转,第10次不跳转。
内层循环每10次一组,前9次跳转,第10次不跳转。
使用1位BHT表
初始时,外层分支指令和内层分支指令的BHT表都是(0),预测为不跳转。
对于内层循环,每10次中,第一次都预测不跳转(0),猜测错误,BHT表更新为(1);剩下8次预测跳转(1),猜测正确,BHT表更新为(1);第10次预测跳转(1),猜测错误,BHT表更新为(0)。正确率为
(
8
∗
10
)
/
100
=
80
%
(8*10)/100 = 80\%
(8∗10)/100=80%。
对于外层循环,10次中,第一次预测不跳转(0),猜测错误,BHT表更新为(1);剩下8次预测跳转(1),猜测正确,BHT表更新为(1);第10次预测跳转(1),猜测错误,BHT表更新为(0)。正确率为
8
/
10
=
80
%
8/10 = 80\%
8/10=80%。
使用2位饱和计数BHT表
11,strongly taken,饱和状态,分支预测跳转。
10,weakly taken,不饱和,分支预测跳转。
01,weakly not taken,不饱和,分支预测不跳转。
00,strongly not taken,饱和状态,分支预测不跳转。
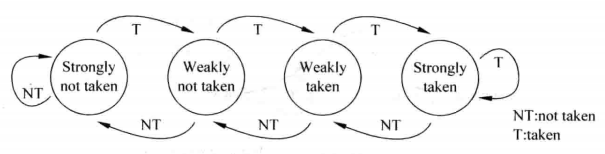
初始时,外层分支指令和内层分支指令的BHT表都是(00),预测为不跳转。
对于内层循环,第一个10次分支中,第一次预测不跳转(00),猜测错误,BHT表更新为(01);第二次预测不跳转(01),猜测错误,BHT表更新为(11);剩余7次预测跳转(11),猜测正确,BHT表更新为(11);第10次预测跳转(11),猜测错误,BHT表更新为(10)。之后的每10次中,第一次预测跳转(10),猜测正确,BHT表更新为(11);剩余8次预测跳转(11),猜测正确,BHT表更新为(11);第10次预测跳转(11),猜测错误,BHT表更新为(10)。正确率为
(
7
+
9
∗
9
)
/
100
=
88
%
(7 + 9*9)/100 = 88\%
(7+9∗9)/100=88%。
对于外层循环,第一个10次分支中,第一次预测不跳转(00),猜测错误,BHT表更新为(01);第二次预测不跳转(01),猜测错误,BHT表更新为(11);剩余7次预测跳转(11),猜测正确,BHT表更新为(11);第10次预测跳转(11),猜测错误,BHT表更新为(10)。正确率为
7
/
10
=
70
%
7/10 = 70\%
7/10=70%。
分析:for (i=0;i<10;i++) for(j=0;j<10;j++) for(k=0;k<10;k++){…}的分支预测正确率。(2021真题题)
解:
按照上一题解即可。
假设浮点指令延迟周期见之前的题目。分支延迟位1个周期,有延迟槽。(2021复习题)
L1: LDCL F0,0(R1)
ADD.D F2,F0,F1
SDCL F2,0(R1)
ADDIU R1,R1,$-8
BNE R1,R2,L1
NOP
1)软件流水。计算周期。
解:
分析,主体循环有两个RAW相关,有三层。循环展开3次:
| i-2 | i-1 | i |
|---|---|---|
| LDCL F0,16(R1) | ||
| ADD.D F2,F0,F1 | LDCL F0,8(R1) | |
| SDCL F2,16(R1) | ADD.D F2,F0,F1 | LDCL F0,0(R1) |
| SDCL F2,0(R1) | ADD.D F2,F0,F1 | |
| SDCL F2,0(R1) |
#装入代码
LDCL F0,0(R1)
ADD.D F2,F0,F1
LDCL F0,-8(R1)
ADDIU R1,R1,$-16
#主体循环
L1:
SDCL F2,16(R1) #需要空1拍,与装入代码的ADD.D RAW相关
ADD.D F2,F0,F1
LDCL F0,0(R1)
ADDIU R1,R1,-8
BNE R1,R2,L1
NOP
#排空代码
SDCL F2, 16(R1)
ADD.D F2,F0,F1 #写回需要再等3拍
SDCL F2,8(R1)
总执行周期数:装入4+1拍,主体循环n-2次,每次循环6拍,排空代码3+2拍,总计6n-2拍。
为了充分利用延迟槽,可以调整ADDIU的位置:
#装入代码
LDCL F0,0(R1)
ADD.D F2,F0,F1
LDCL F0,-8(R1)
ADDIU R1,R1,$-24
#主体循环
L1:
SDCL F2,24(R1) #需要空1拍,与装入代码的ADD.D RAW相关
ADD.D F2,F0,F1
LDCL F0,8(R1)
BNE R1,R2,L1
ADDIU R1,R1,-8
#排空代码
SDCL F2, 24(R1)
ADD.D F2,F0,F1 #写回需要再等3拍
SDCL F2,16(R1)
总时间4+1+5*(n-2)+3+2 = 5n拍。
第九章 功能部件
假设每个“非门”“与非门”“或非门”的扇入不超过4个,且每个门的延迟为T,请给出使用如下不同算法的16位加法器的延迟。(1)串行进位加法器(2)先行进位加法器(3)说明为何先行进位加法器能比串行进位加法器快。(2021复习题)
解:
(1)串行进位加法器
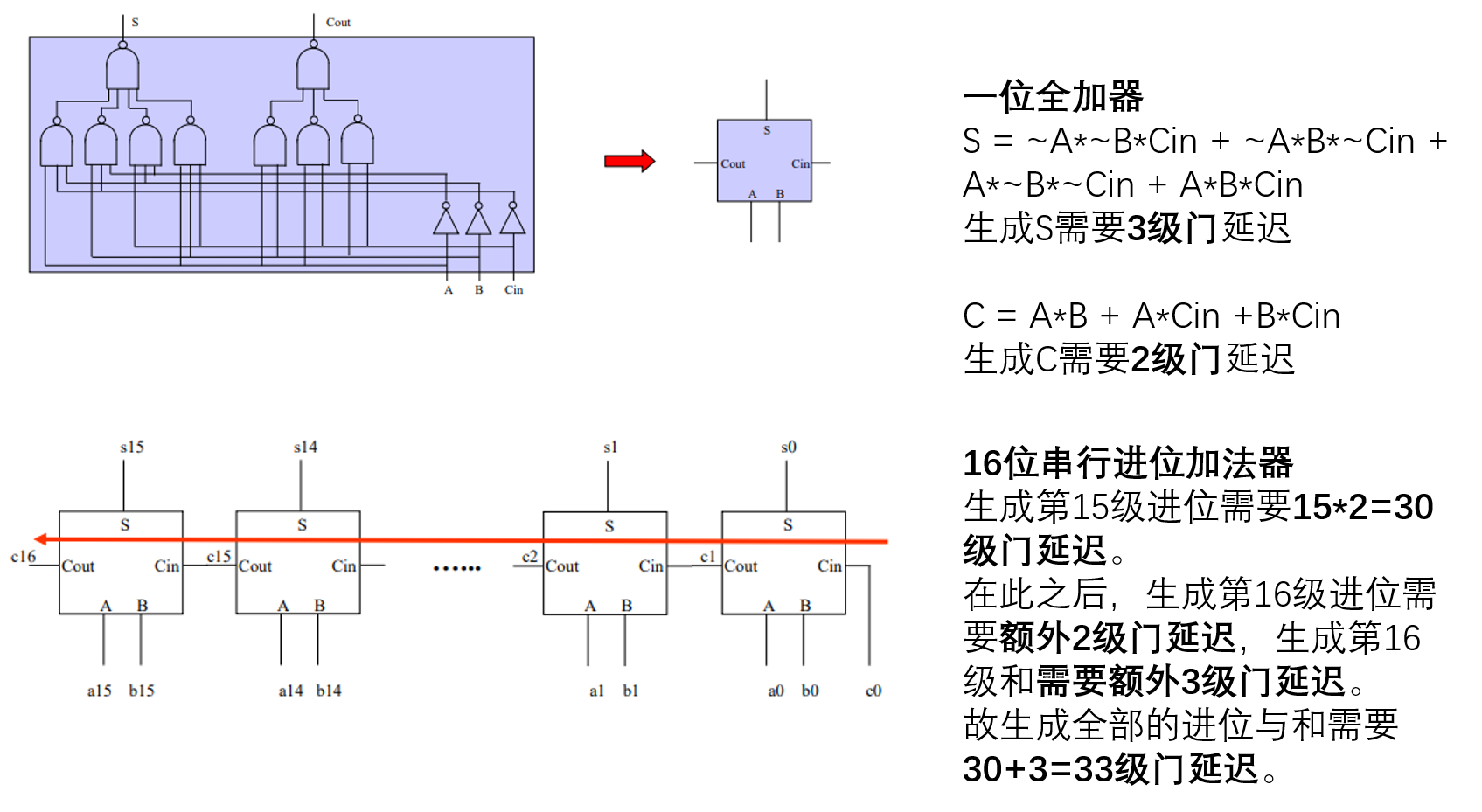
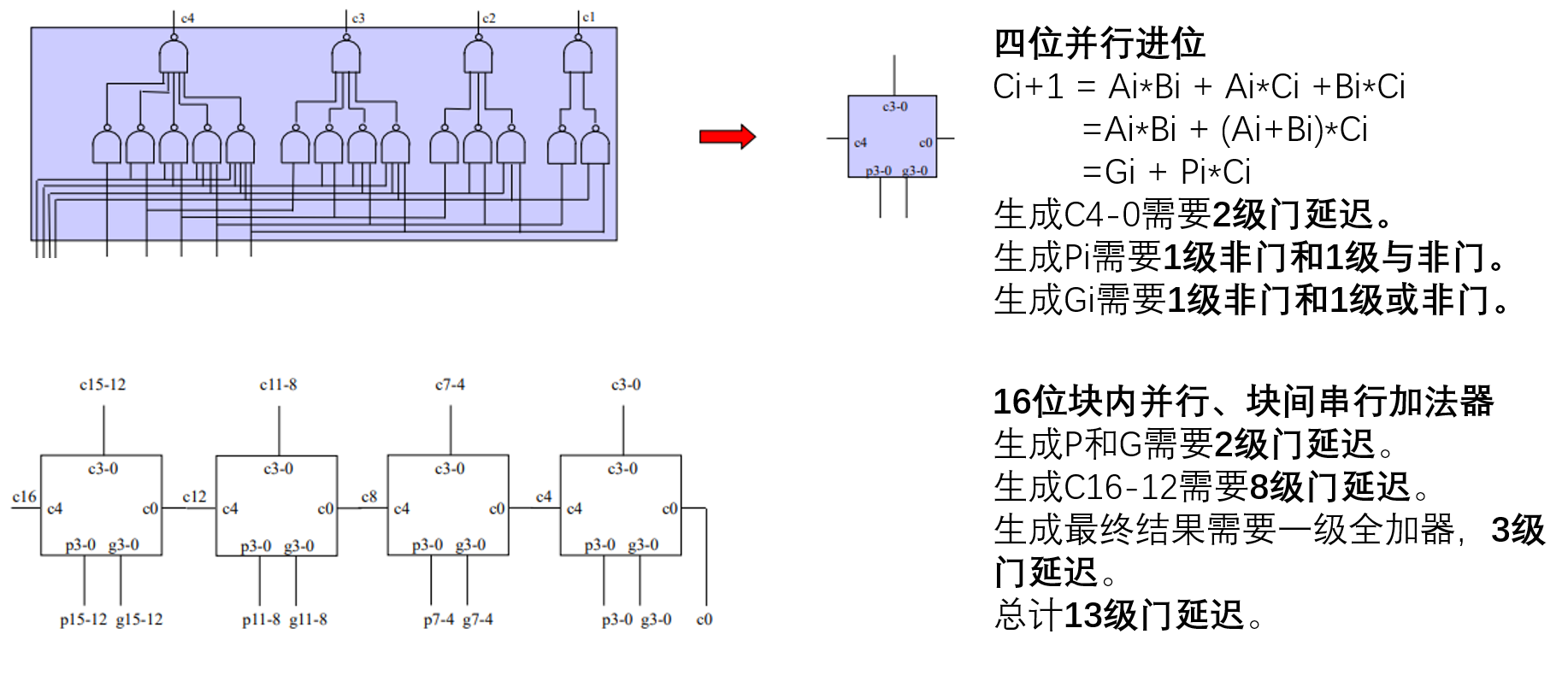
(2)先行进位加法器
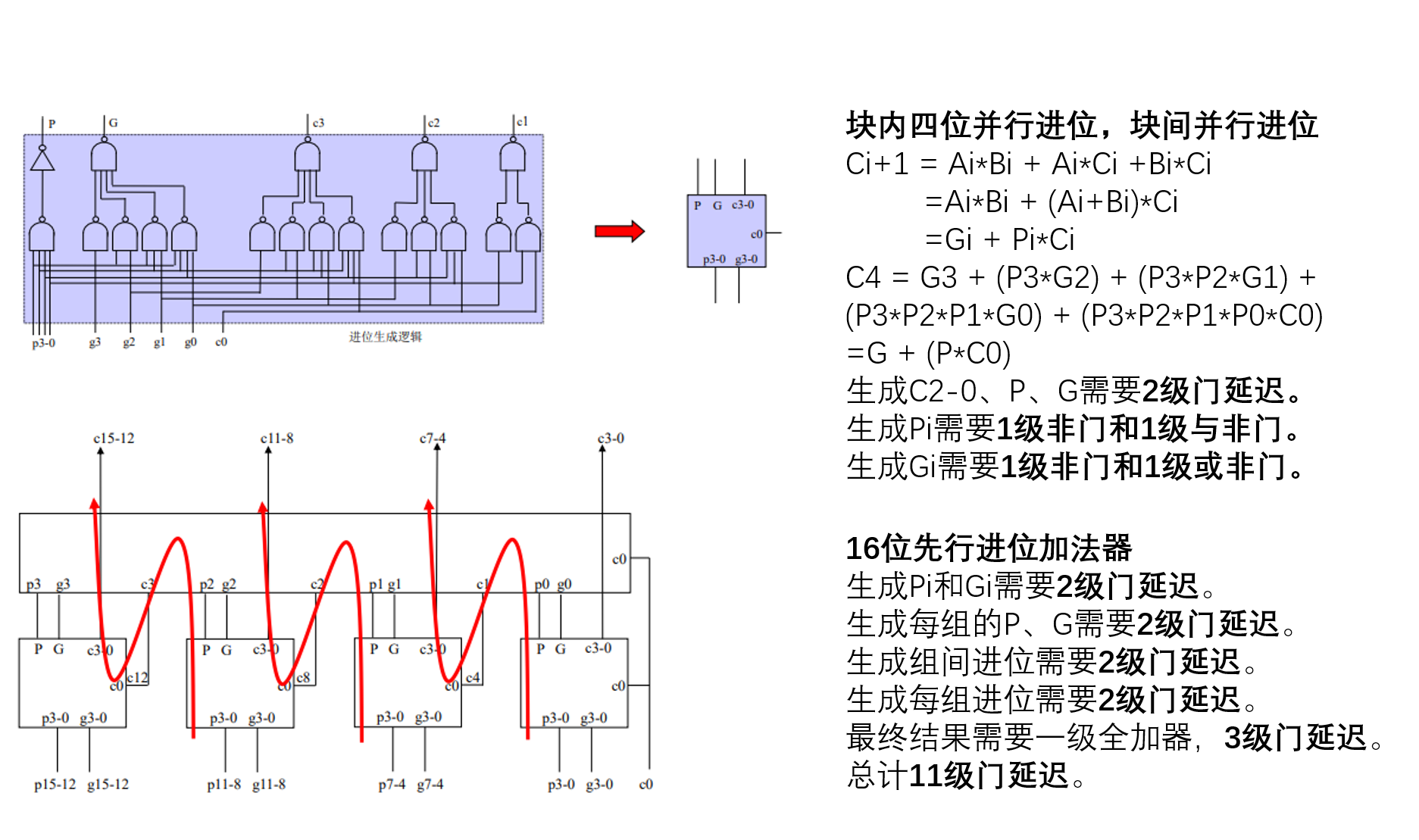
(3)先行进位加法器快的原因是它能更快地生成第 i 位的 c 而不需要依赖于第 i-1位的 c。
假设每个“非门”“与非门”“或非门”的扇入不超过4个,且每个门的延迟为T,请给出使用如下不同算法的把4个16位数相加的延迟。(1)使用多个先行进位加法器 (2)使用华莱士树及先行进位加法器。(2021复习题)
解:
(1)多个先行进位加法器
四个16位数A、B、C、D,可以用两个先行进位加法器计算E = (A+B)和F = (C+D),11级门延迟。
再用一个先行进位加法器计算S = (E+F),11级门延迟。
总计22级门延迟。
(2)华莱士树及先行进位加法器
华莱士树的每一层,可以将3n个1位数相加变为2n个1位数相加。
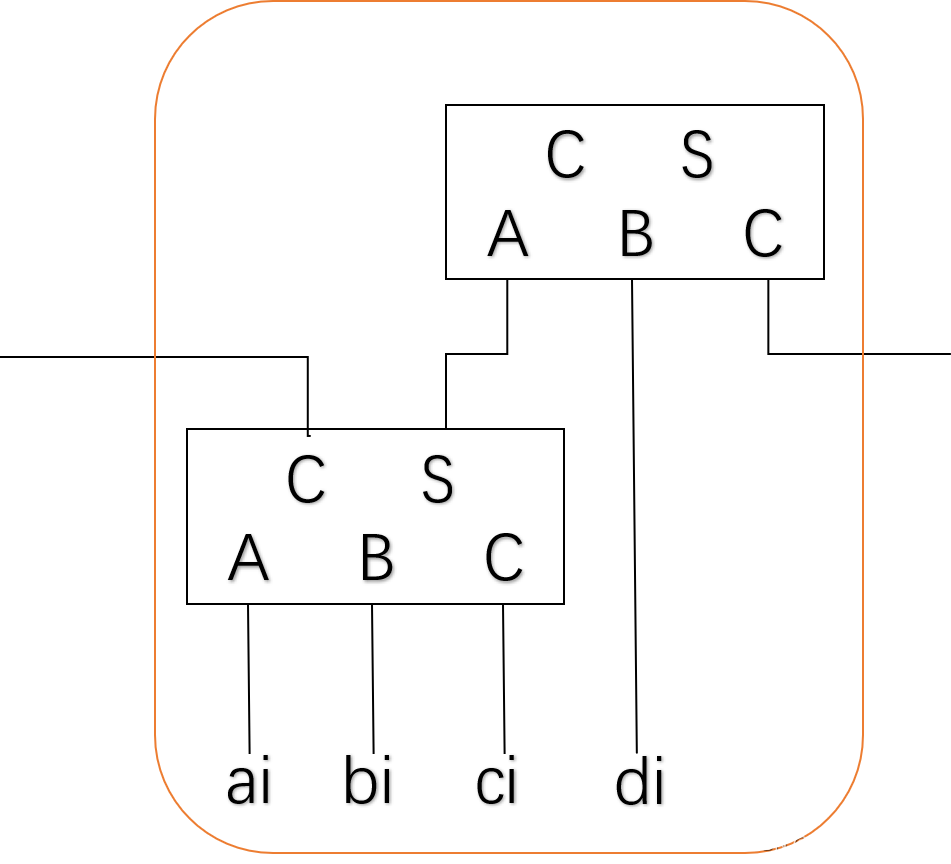
两层的华莱士树即可以将4个1位数变为2个1位数相加。16个并行的两层华莱士树即可以将4个16位数变为2个16位数相加。6级门延迟。
之后使用一个先行进位加法器,11级门延迟,总计17级门延迟。
16位华莱士树的结构(2020真题)

构造时,接收的进位输入信号,必须接到进位输出该信号层次的上一层或更高。
16输入,第一层16 mod 3 = 5个全加器,接入15个输入,剩余1输入接到第二层。
第二层,(5*2 + 1) mod 3 = 3个全加器,接入第一层输出的5个S,第一层未接入的1输入,和上一个华莱士树第一层输出的3个C,剩余2个C接到第三层。
第三层,(3*2 + 2)mod 3 = 2个全加器,外加一个半加器,接入第二层输出的3个S,第二层未接入的2个C,和上一个华莱士树第二层输出的3个C。
第四层,(3*2) mod 3 = 2个全加器,接入第三层输出的3个S,和上一个华莱士树第三层输出的3个C。
第五层,(2*2) mod 3 = 1个全加器,接入第四层输出的2个S,和上一个华莱士树第四层输出的1个C,剩余1个C接到第六层。
第六层,(2 + 1)mod 3 = 1个全加器,接入第五层输出的1个S,和上一个华莱士树第四层输出的1个C,和上一个华莱士树第五层输出的1个C。
16位先行进位加法器的Verilog实现(2019、2021真题)
module C4(p,g,cin,P,G,cout)
input [3:0] p,g;
input cin;
output P,G;
output[2:0] cout;
assign P = &p; //P = p3*p2*p1*p0
assign G = g[3] | (p[3]&g[2]) | (p[3]&p[2]&g[1]) | (p[3]&p[2]&p[1]&g[0]);
assign cout[0] = g[0] | (p[0]&cin);
assign cout[1] = g[1] | (p[1]&g[0]) | (p[1]&p[0]&cin);
assign cout[2] = g[2] | (p[2]&g[1]) | (p[2]&p[1]&g[0]) | (p[2]&p[1]&p[0]&cin);
endmodule
module 16add(a,b,cin,s,cout)
input [15:0] a,b;
input cin;
output[15:0] s;
output cout;
wire [15:0] p = a|b; //pi = ai + bi
wire [15:0] g = a&b; //gi = ai*bi
wire [3:0] P,G;
wire [15:0] c; //1-16的向上进位
assign c[0] = cin;
C4 C0_3(.p(p[3:0]),.g(g[3:0]),.cin(c[0]),P(P[0]),.G(G[0]),.cout(c[3:1])); //c4块间并行
C4 C4_7(.p(p[7:4]),.g(g[7:4]),.cin(c[4]),P(P[1]),.G(G[1]),.cout(c[7:5]));//c8块间并行
C4 C8_11(.p(p[11:8]),.g(g[11:8]),.cin(c[8]),P(P[2]),.G(G[2]),.cout(c[11:9]));//c12块间并行
C4 C12_15(.p(p[15:12]),.g(g[15:12]),.cin(c[12]),P(P[3]),.G(G[3]),.cout(c[15:13]));//c16是cout
C4 C_INTER(.p(P[3:0]),.g(G[3:0]),.cin(c[0]),P(),.G(),.cout({c[12],c[8],c[4]}));//块间并行
assign cout = a[15]&b[15] | a[15]&c[14] | b[15]&c[14];
assign s = (~a&~b&c)|(~a&b&~c)|(a&~b&~c)|(a&b&c);
endmodule
第十章 高速缓存
一个处理器的页大小为4KB,一级数据cache大小为64KB,cache块的大小为32B,指出在直接相联、二路相联,以及4路相联的情况下需要页着色(page coloring)的地址位数和最少需要的物理地址TAG大小。(2019、2020、2021真题,仅改动数字)
解:
页大小为
4
K
B
=
2
12
B
4KB=2^{12}B
4KB=212B,页内地址为
[
11
:
0
]
[11:0]
[11:0]位。
Cache容量
64
K
B
=
2
16
B
64KB=2^{16}B
64KB=216B,地址范围为
[
15
:
0
]
[15:0]
[15:0]。
Cache 块大小为
32
B
=
2
5
B
32B=2^5B
32B=25B,
B
l
o
c
k
−
o
f
f
s
e
t
Block-offset
Block−offset地址范围为
[
4
:
0
]
[4:0]
[4:0]。
1)直接相连:
Cache
I
n
d
e
x
Index
Index位数为地址的
[
15
:
5
]
[15:5]
[15:5],需要页着色的是地址
[
15
:
12
]
[15:12]
[15:12],共 4 位。TAG大小为物理地址位数-15。
2)二路组相联:
Cache
I
n
d
e
x
Index
Index索引位数为地址的
[
14
:
5
]
[14:5]
[14:5],需要页着色的是地址
[
14
:
12
]
[14:12]
[14:12],共 3 位。TAG大小为物理地址位数-14。
3)四路组相联:
Cache
I
n
d
e
x
Index
Index索引位数为地址的
[
13
:
5
]
[13:5]
[13:5],需要页着色的是地址
[
13
:
12
]
[13:12]
[13:12],共 2 位。TAG大小为物理地址位数-13。
补充知识:页着色
页着色技术,需要在VIPT结构的Cache中使用,即用虚拟地址索引,物理地址匹配Tag。
当VIPT的Cache,其每一路的容量大于页大小的时候,会出现Cache别名问题。
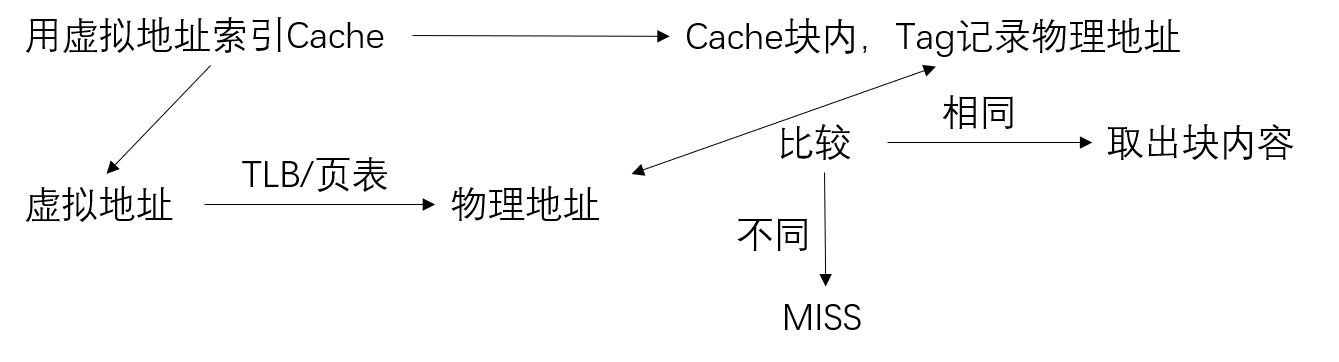
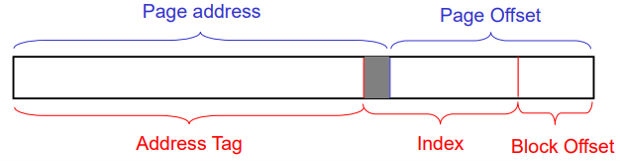
考虑如下情况:
32位机器,虚地址V1:0xe0001120 虚地址V2:0xf0002120,都映射到物理地址P: 0x00000120。
页大小4KB,占地址的低12位。于是虚拟地址和物理地址的第12位一定相同。
当Cache每路的大小不超过页大小时,用来
i
n
d
e
x
index
index的地址位在
[
11
:
0
]
[11:0]
[11:0]之间,于是V1和V2的
i
n
d
e
x
index
index相同,在Cache中索引到同一项,于是不会出现别名。
当Cache每路的大小超过页大小时,如每路容量8KB,用来
i
n
d
e
x
index
index的地址位在
[
12
:
0
]
[12:0]
[12:0]之间。而V1和V2的第13位不同,于是索引到Cache的不同行,于是出现了同一物理地址的多处备份,也即别名。
为解决别名问题,引入软件的页着色,它保证,在给虚拟地址分配物理地址时,如果两个虚拟地址映射到同一物理地址,要求两个虚拟地址的页着色位相同,即上图中对应Cache
I
n
d
e
x
Index
Index与
P
a
g
e
−
o
f
f
s
e
t
Page-offset
Page−offset之间差额的灰色部分相同。
第十一章 存储管理
一台Linux操作系统(页大小为4KB)的MIPS计算机上执行如下C语言程序。程序memcpy函数执行过程中可能发生哪些例外?各多少次。(2019、2020真题)
void cycle(double *a){
int i;
double b[65536];
for(i=0;i<3;i++)
memcpy(a,b,sizeof(b));
}
以MIPS体系结构为例,包括三类共四种例外:
(1) TLB refill 例外:当访问的虚地址在TLB表中没有映射表项时发生。在MIPS中,一次refill会向TLB中填入一对奇偶页的映射关系。
(2) TLB invalid 例外:找到虚地址匹配项,但v=0。通常发生在虚地址只分配了物理页号,但还没有初始化页面的时候,以及物理页面被从内存换出的时候。
(3) TLB modify 例外:找到虚地址匹配项,v=1,但D=0且访问为store,即非法修改只读页。
本题中,a和b各占
2
19
B
2^{19}B
219B,页大小
2
12
B
2^{12}B
212B,也即各占
2
7
=
128
2^7=128
27=128页。
第一层循环:
a与b都各自需要128个页表项。假设TLB足够大,每个TLB表项映射连续的奇偶两页,并假设a与b都从奇数页的开头开始。那么第一次访问a和b时,会各触发
128
/
2
=
64
128/2 = 64
128/2=64次TLB Refill,填入TLB表项。但是由于页面没有初始化,会紧接着各触发
128
128
128次TLB Invalid例外。总计
(
64
+
128
)
∗
@
=
384
(64+128)*@ = 384
(64+128)∗@=384次TLB例外。
第二层与第三层循环,假设TLB没有替换,内存也没有换页,那么不触发TLB例外。
一台Linux操作系统(页大小为4KB)的MIPS计算机上执行如下C语言程序。函数执行过程中可能发生哪些例外?各多少次。TLB 32表项,采用LRU替换策略。a、b、c均以8192KB对齐。(2021真题)
void cycle(double *a){
int i;
double a[32768];
double b[32768];
double c[65536];
memset(0,c,sizeof(c));
for(i=0;i<3;i++)
{
for(j=0;j<32768;j++)
{
c[2*j] = a[j];
c[2*j+1] = b[j];
}
}
}
假设某一CPU的Cache中需要64位虚拟地址,8位进程标识,而其支持的物理内存最多64GB.请问,使用虚拟地址索引比使用物理地址索引的TAG大多少?这个值是否随着Cache块大小的变化而发生改变?(2021复习题)
解:
虚地址TAG:64+8 - index - block_offset = 72 - index - block_offset。(虚地址+进程标识的访问方式保护了进程间的内存访问。)
物理地址TAG:36 - index - block_offset 。
差值为36。
改变块的大小,亦或改变 cache 的其它参数,cache 占据的地址的低位的长度对于虚地址和物理地址都是一样的,所以对于 cache 的 tag 而言,两中索引方式相差位数保持不变。
已知一台计算机的虚地址为 48 位,物理地址为 40 位,页大小为 16KB,TLB 为 64 项全相联,TLB 的每项包括一个虚页号 vpn,一个物理页号 pfn,以及一个有效位 valid,请根据如下模块接口写出一个 TLB 的地址查找部分的 Verilog 代码。(2021复习题)
module tlb_cam(vpn_in, pfn_out, hit,…);
其中 vpn_in 为输入的虚页号,pfn_out 为输出的物理页号,hit 为表示是否找到的输出信号,
“…”表示与该 TLB 输入输出有关的其他信号。重复的代码可以用“…”来简化。
解:
module tlb_cam(vpn_in,pfn_out,hit,valid_out)
input [33:0] vpn_in; //虚地址的48-15位,低14位是页内偏移
output [25:0] pfn_out; //物理地址的40-15位
output hit;
output valid_out;
reg [60:0] cam_content [63:0]; //64项寄存器,每个寄存器34 + 26 + 1 =61位
wire [63:0] entry_hit;
assign hit = | entry_hit; //按位或
assign entry_hit[0] = (vpn_in == cam_content[0][33:0]);
...
assign entry_hit[63] = (vpn_in == cam_content[63][33:0]);
assign pfn_out = {26{entry_hit[0]}} & cam_content[0][59:34] |
...
{26{entry_hit[63]}} & cam_content[63][59:34];
assign valid_out = entry_hit[0] & cam_content[0][60] || //逻辑或
...
entry_hit[63] & cam_content[63][60];
endmodule
第十二章 多处理器
假设在一个双CPU多核处理器系统中,两个CPU用单总线连接,并且采用监听一致性协议(MSI),cache的初始状态均为无效,然后两个CPU对内存中同一数据块进行如下操作:CPU A读,CPU A写,CPU B写,CPU A读,写出每次访问后两个CPU各自的cache状态变化。(2019真题)
解:
监听一致性协议:利用总线将处理器核的私有Cache 和主存储器连接在一起,每一个私有 Cache 中的控制器会时刻侦听总线上的消息,并根据消息的类型做出相应的操作。
Modified(已修改):块已在缓存中已被修改,缓存中的数据与后备存储器(例如内存)中的数据不一致。具有“M”状态的块的缓存在该块被替换时需要将其中的内容写回后备存储。
Shared(共享):块未被修改,并在至少一个处理器的缓存中以只读状态存在。高速缓存可以将其替换而不将其中的数据写回后备存储。
Invalid(无效):该块不存在于当前缓存中,或者因为总线请求而被标记为无效。如果要将某个块存储在该缓存中,则必须首先从内存或另一个高速缓存中获取该块。
| 事件 | A状态 | B 状态 |
|---|---|---|
| 初始 | I | I |
| CPU A读 | S | I |
| CPU A写 | M | I |
| CPU B写 | I | M |
| CPU A读 | S | S |
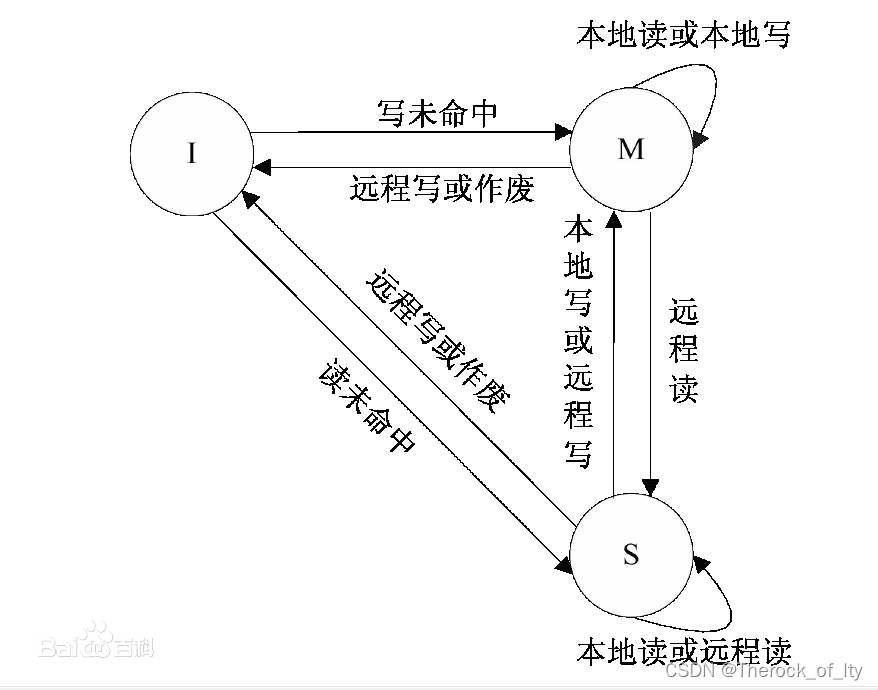
假设在一个三CPU多核处理器系统中,三个CPU采用目录协议,并且采用监听一致性协议(MSI)(2021真题)
掌握ESI与目录一致性协议(2020)
目录一致性协议要求有一个处于中央控制地位的处理器,其持有目录并用于协调各个处理器。
E(Exclusive,独占):表明对应Cache 行被当前处理器核独占,当前处理器核可以随意读写,其他处理器核如果想读写这个cache 行需要请求占有这个cache 块的处理器核释放该Cache行。
S(Shared,共享):表明当前Cache行可能被多个处理器核共享,只能读取,不能写入。
I (Invalid,无效):表明当前Cache块是无效的。
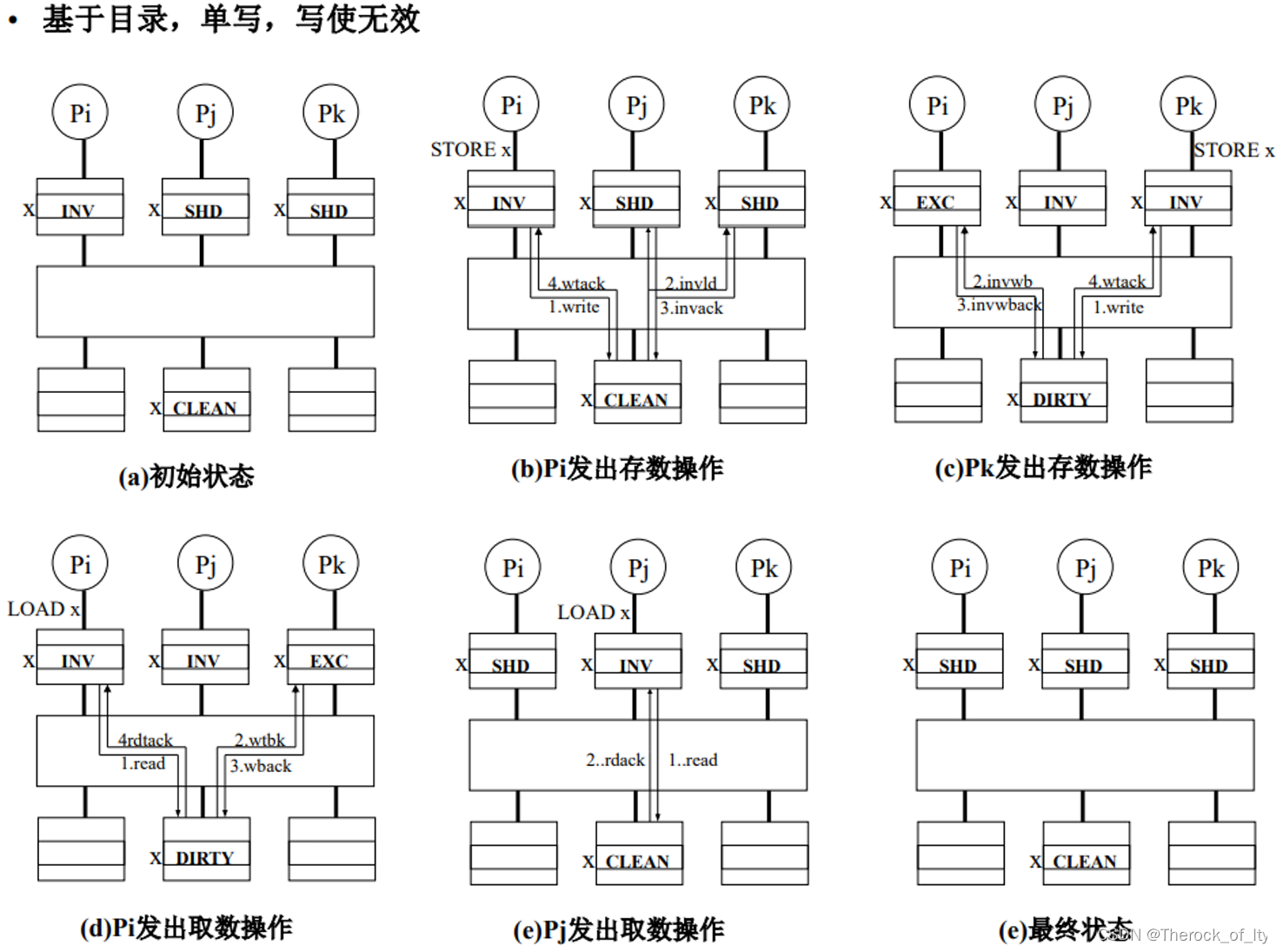
a)初始状态,目录中块X为CLEAN,Pi为INV,Pj和Pk为SHD。
b)Pi发出store操作。Pi向目录申请write,目录通告Pj和Pk invalid。Pj和Pk状态设置为INV,并回复invalid ack。目录通告Pi,write ack允许写,并记录下X的备份在Pi,修改状态为DIRTY。Pi修改状态为EXC。
c)Pk发出store操作。Pk向目录申请write,目录通告Pi invalid和write back。Pi回复invalid writeback ack,回传一个修改备份给目录。目录更新备份,发送给Pk,并write ack允许写,并记录下X的备份在Pk,修改状态为DIRTY。Pk修改状态为EXC。
d)Pi发出load操作。Pi向目录申请read,目录通告Pk write back。Pk回复 writeback ack,回传一个修改备份给目录。目录更新备份,发送给Pi,并read ack允许读,并记录下X的备份在Pk与Pi,修改状态为CLEAN。Pi和Pk修改状态为SHD。
e)Pj发出load操作。Pj向目录申请read,目录将备份发送给Pj,并read ack允许读,并记录下X的备份在Pk、Pj和Pi。Pj修改状态为SHD。
状态,目录中块X为CLEAN,Pi为INV,Pj和Pk为SHD。
b)Pi发出store操作。Pi向目录申请write,目录通告Pj和Pk invalid。Pj和Pk状态设置为INV,并回复invalid ack。目录通告Pi,write ack允许写,并记录下X的备份在Pi,修改状态为DIRTY。Pi修改状态为EXC。
c)Pk发出store操作。Pk向目录申请write,目录通告Pi invalid和write back。Pi回复invalid writeback ack,回传一个修改备份给目录。目录更新备份,发送给Pk,并write ack允许写,并记录下X的备份在Pk,修改状态为DIRTY。Pk修改状态为EXC。
d)Pi发出load操作。Pi向目录申请read,目录通告Pk write back。Pk回复 writeback ack,回传一个修改备份给目录。目录更新备份,发送给Pi,并read ack允许读,并记录下X的备份在Pk与Pi,修改状态为CLEAN。Pi和Pk修改状态为SHD。
e)Pj发出load操作。Pj向目录申请read,目录将备份发送给Pj,并read ack允许读,并记录下X的备份在Pk、Pj和Pi。Pj修改状态为SHD。